Just a fun one for today. No outlandish Bayesian-based philosophy, just straight up classical significance tests. I will even take it relatively gently for those of you who are not “into” statistics, because today’s fun is for everybody!
So, the question of the day is “if I pick a random digit of pi (that I don’t know in advance of course), is it equally probable to be any of 0 to 9?”. Actually one could go a lot deeper into this question than I am going to, and look for correlations and all sorts of things, but we will just look at the statistics of some big samples of the first digits of pi.
Disclaimer: I am not going to calculate these digit frequencies myself, due to “effort minimisation” ;). The following data comes from this website, and I have made no effort to verify its accuracy. So with that in mind, here is a histogram of the frequencies with which the digits 0 to 9 appear in the first three billion digits of pi:

Pretty damn uniform looking right? Lets zoom in a bit:

Note the scale on the y axis. We are looking at fractional variations of around 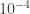

The simplest statistical test we can do is to calculate the p-value for this data, under the “null hypothesis” that the digits are randomly sampled from the options of 0 to 9, with equal probability for each option. This is the equivalent of having a bag with equal numbers of tiles with the digits 0 to 9 written on them, say 10 of each, and reaching into this bag to pull out the next digit of pi (and then putting the tile back after each draw to avoid messing up the probabilities on the next draw). This process will give you sets of numbers whose properties follow the famous binomial distribution:

for 

For our case, 






The relevant properties of the binomial distribution that we need to consider are the expected value and the variance; i.e. we want to know how many occurrences of

Plugging in our numbers (for n = 3 billion) we get E = 0.3 billion (i.e. on average every number should appear one tenth of the time – as one knows intuitively), and Var ~ 0.3 billion also. However the variance is not very intuitive I find, generally the standard deviation is better (the square root of the variance) since we have an intuitive understanding of it thanks to the normal distribution. So for us the standard deviation is 
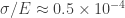
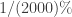
There are two more pieces of information I must mention before we can actually do our statistical test. The first I alluded to a moment ago — that is, the binomial distribution is asymptotically normal, which just means that for large sample sizes we can use the normal distribution (with mean and variance given by the formulae above) instead of the binomial distribution, and we will get the same answers. Our sample size of 3 billion is vast so this approximation is essentially exact, and life will be much easier if we work with normal distributions, so we will. The second involves a property of samples from normal distributions. This is that if we take the sum of the squares of normally distributed random variables (shifted by their means and scaled by their variance), then the resulting sum is a random variable that follows the famous chi-squared distribution. In equation form, if we have 

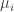


and where 

We are now ready to do our test! So, what is it that we want to know? There are many questions we may ask of our data and each requires a different test. However, the most obvious one to ask is whether the observed digit frequencies sit around the expect values of 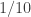
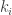



The statistical question now solidifies into asking “assuming the null hypothesis is true, what is the probability of observing data which gives a value of 

For brevity, I must leave it to you to wikipedia chi-squared distribution to see what this distribution looks like and get and idea of what this integral means. Suffice it to say it requires numerical evaluation, but any statistics package or library will have routines do this so just pick your favourite. I am a Python guy so I use the scipy.stats package.
So now I will skip to the punchline, which is that according to this test, with the null hypothesis as described and using the data I stole from the linked website, I compute

This means that there is a 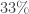

The final warning is that this test considers only the value of

Pingback: The pi is a lie! | Casual Calculations